
Multimodal Representation Loss Between Timed Text and Audio for Regularized Speech Separation
Published in Proc. Interpseech, 2024
Multimodal Representation Loss for Regularized Speech Separation
The paper “Multimodal Representation Loss Between Timed Text and Audio for Regularized Speech Separation” presents a novel approach to improving speech separation models by leveraging textual modalities for regularization. This method, called Timed Text-based Regularization (TTR), utilizes language model-derived semantics during the training phase to improve the quality of separated audio sources, without requiring auxiliary text data during inference. Let’s dive into the core components and experimental findings of this research.
Challenges in Speech Separation
Speech separation, the task of isolating individual speech signals from a mixture, has seen substantial improvements with deep learning approaches. Methods like Conv-TasNet and Dual-Path RNN have popularized end-to-end solutions by replacing traditional time-frequency feature extraction with raw waveform encoding and separation. These approaches have improved both temporal and spatial modeling, allowing for better performance in separating mixed audio.
Another trend in improving speech separation has been the use of auxiliary modalities, such as visual or textual cues, to condition the separation system. For example, Text-Informed Separation allows users to specify a target sound source using a textual description. However, while using such auxiliary information for conditioning is effective, it is often impractical, especially during real-time use, due to the need for detailed metadata.
Introducing Timed Text-based Regularization (TTR)
The proposed TTR method addresses the limitations of previous approaches by incorporating textual modalities during the training phase only. Specifically, TTR uses embeddings from WavLM (an audio model) and BERT (a language model) to create a multimodal representation loss that encourages the separated audio sources to be aligned with their corresponding timed text descriptions. This multimodal loss effectively regularizes the separation model, ensuring that the separated sources capture meaningful sentence-level semantics from the text. See details in Figure 1.
Overview of the Approach
- Pretrained Audio and Language Models: The method starts with pretrained WavLM and BERT models to extract phonetic and semantic features, respectively. These embeddings are used to compare the alignment between separated audio and corresponding text during training.
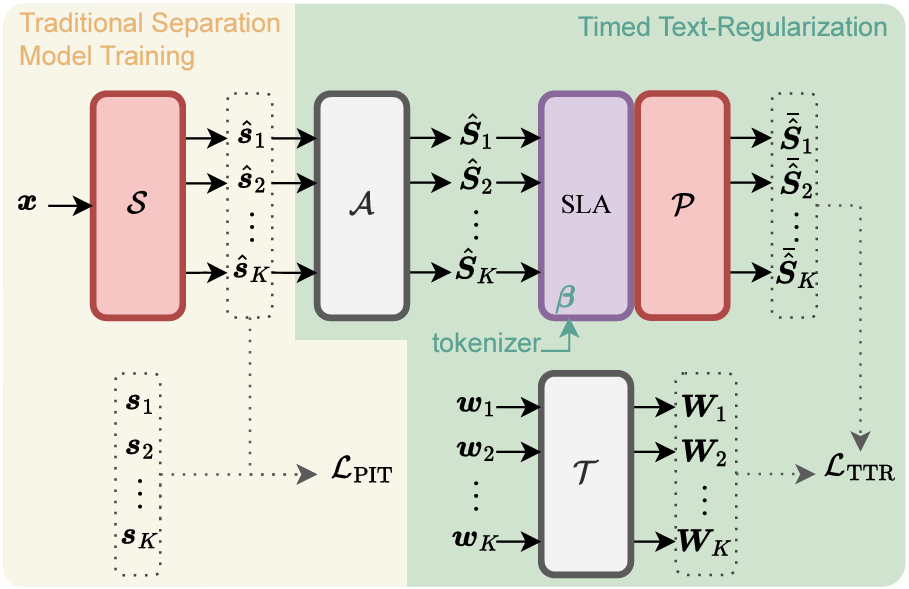
Figure 1: The proposed TTR-SS training pipeline.
Summarizer Transformer: A Transformer-based audio summarizer is learned to align the audio and word embeddings, bridging the gap between these modalities. This summarizer consists of two main components: the Subword-Level Summarizer and the Sentence-Level Aggregator, which convert frame-level audio features into meaningful vectors that align with subword and sentence-level representations.
Subword-Level Alignment (SLA): To align the textual and audio embeddings, the Subword-Level Alignment (SLA) module uses known word boundaries to divide audio embeddings into subword-specific segments. This alignment helps create a representation that captures the correspondence between the spoken content and the textual description.
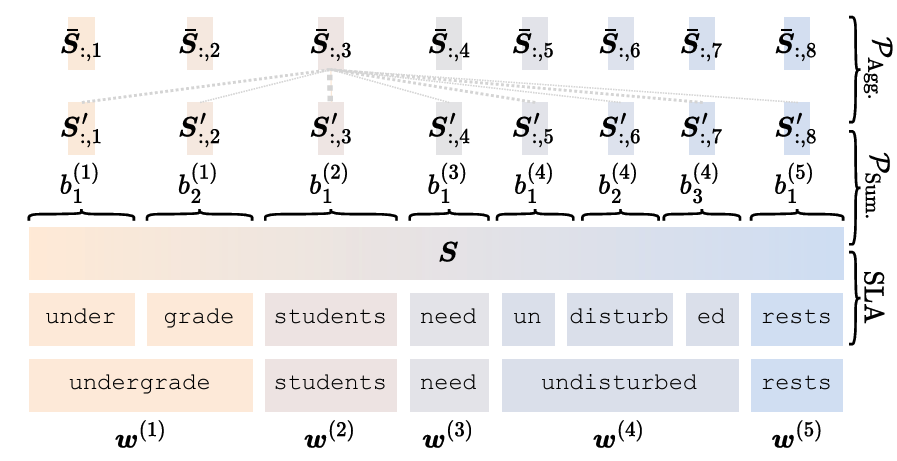
Figure 2: The Subword-Level Alignment (SLA) and Summarizer Transformer components.
The Subword-Level Alignment (SLA) module takes advantage of word boundaries to divide audio embeddings into segments corresponding to subwords. This segmentation allows for better alignment between the text and the audio embeddings, ensuring that each subword embedding is matched with its relevant audio features. Figure 2 illustrates how SLA divides the audio embeddings and how the summarizer Transformer aggregates these segments into meaningful representations that align with the subword and sentence-level semantics from the language model.
The summarizer, along with WavLM and BERT, is incorporated as a regularizer in the training of the separation model. Importantly, this regularization does not add any computational overhead during inference since the text is used only during training.
Experimental Setup and Results
The experiments were conducted using the LibriMix dataset, which includes both two-speaker and three-speaker mixtures in clean and noisy environments. Two baseline models were used for comparison: Conv-TasNet and SepFormer.
Evaluation Metrics
The performance of the models was evaluated using standard metrics such as:
- Scale-Invariant Source-to-Distortion Ratio (SI-SDR): Measures the quality of separated sources compared to the original signals.
- Short-Time Objective Intelligibility (STOI): Measures the intelligibility of separated sources.
- Source-to-Distortion Ratio (SDR): Evaluates the overall quality of the separation.
Performance Improvements
Table 1 below shows the improvements in performance metrics after incorporating the TTR method. The TTR-SS approach consistently outperformed the baselines in both clean and noisy conditions, with the SepFormer + TTR model showing particularly notable improvements.
| Task | Model | SDR Improvement (dB) | SI-SDR Improvement (dB) | STOI |
|---|---|---|---|---|
| Libri2Mix (Clean) | Conv-TasNet | 15.11 | 14.76 | 0.9311 |
| Conv-TasNet + TTR | 15.44 | 15.10 | 0.9344 | |
| SepFormer | 18.68 | 18.35 | 0.9574 | |
| SepFormer + TTR | 20.17 | 19.87 | 0.9685 | |
| Libri2Mix (Noisy) | Conv-TasNet | 12.36 | 11.80 | 0.8490 |
| Conv-TasNet + TTR | 12.47 | 11.90 | 0.8512 | |
| SepFormer | 15.11 | 14.54 | 0.8949 | |
| SepFormer + TTR | 15.98 | 15.36 | 0.9096 | |
| Libri3Mix (Clean) | Conv-TasNet | 12.40 | 11.98 | 0.8365 |
| Conv-TasNet + TTR | 12.82 | 12.41 | 0.8448 | |
| SepFormer | 17.26 | 16.91 | 0.9141 | |
| SepFormer + TTR | 18.45 | 18.09 | 0.9292 | |
| Libri3Mix (Noisy) | Conv-TasNet | 10.93 | 10.39 | 0.7669 |
| Conv-TasNet + TTR | 11.41 | 10.88 | 0.7793 | |
| SepFormer | 14.73 | 14.24 | 0.8489 | |
| SepFormer + TTR | 15.94 | 15.42 | 0.8727 |
Table 1: Source separation performance comparison with and without TTR.
Key Insights
- Performance Gains Across Models: The TTR-SS approach improved all evaluation metrics across different models and datasets. SepFormer + TTR demonstrated the largest gains, suggesting that the more complex Transformer-based architecture benefited most from the additional semantic context provided by TTR.
- No Inference Overhead: One significant advantage of the TTR method is that it does not increase the computational cost during test-time inference. The regularization is applied only during training, making this approach both effective and efficient.
Conclusion
The Timed Text-based Regularization (TTR) method provides a powerful way to improve speech separation models by incorporating semantic information during training. By leveraging pretrained language and audio models, the TTR loss aligns audio representations with corresponding text, which enhances the ability of the model to produce more intelligible and higher-quality separated audio. Importantly, this is achieved without adding any computational burden during inference.
The TTR method shows significant potential, particularly for more complex separation models like SepFormer, where it provides a boost in all key performance metrics. This work represents a step forward in multimodal learning for speech processing, paving the way for more robust and efficient speech separation solutions in real-world applications.