
On the Importance of Neural Wiener Filter for Resource Efficient Multichannel Speech Enhancement
Published in Proc. ICASSP, 2024
Efficient Multichannel Speech Enhancement Using Neural Wiener Filter
Speech enhancement in real-world applications often faces challenges due to environmental noise, reverberation, and the limitations of available computational resources. The paper titled “On the Importance of Neural Wiener Filter for Resource Efficient Multichannel Speech Enhancement” presents a framework designed for efficient multichannel speech enhancement with a focus on low latency and reduced computational complexity. Let’s dive into how this framework works and its innovative features.
Challenges in Multichannel Speech Enhancement
Traditional multichannel speech enhancement methods often rely on deep learning models that work in the frequency domain to improve the short-time Fourier transform (STFT) of noisy speech. These methods typically involve multiple stages of processing, including traditional filters like the Multichannel Wiener Filter (MCWF), Minimum Variance Distortionless Response (MVDR), and Generalized Eigenvalue (GEV) beamformers. While effective, these frequency-domain methods can be computationally expensive and exhibit numerical instability, especially during matrix inversion, which poses challenges in real-time scenarios.
Recent advances have focused on sequential neural beamforming, where the enhancement process involves multiple stages of filtering and processing through deep learning models. This sequential approach enhances the robustness of downstream applications, such as Automatic Speech Recognition (ASR) and speaker verification.
Introducing the Neural Wiener Filter (NWF)
The authors propose a time-domain framework for multichannel speech enhancement that incorporates two compact deep neural networks (DNNs) surrounding a novel Neural Wiener Filter (NWF). Unlike conventional Wiener filters, which operate in the frequency domain, this filter is trained end-to-end alongside other model components, providing better adaptability and efficiency.
Key Components of the Framework
First Deep Neural Network (DNN1): This network processes the noisy multichannel input to produce an intermediate single-channel enhanced speech signal. This output is then used to estimate the NWF coefficients.
Neural Wiener Filter (NWF): The NWF takes inspiration from the traditional frequency-domain Wiener filter but works in the time domain. It adapts the analysis and synthesis transforms for the specific requirements of low-latency enhancement. By jointly optimizing the NWF with other components, the model can produce high-quality enhanced speech with minimal nonlinear distortions.
Second Deep Neural Network (DNN2): After the NWF processes the noisy mixture, DNN2 refines the output to further reduce distortions, resulting in the final enhanced speech.
The entire process is designed to work with a low algorithmic latency of just 2 milliseconds, making it suitable for real-time speech enhancement scenarios.
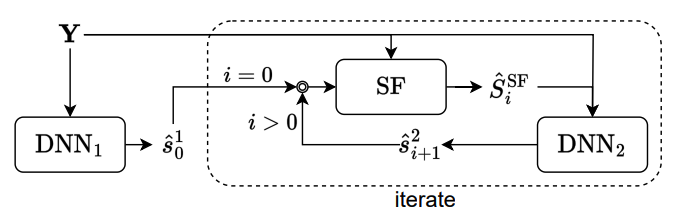
Figure 1: Workflow of sequential neural beamforming using Neural Wiener Filter.
Training Approach and Efficiency
The authors emphasize that joint training of all components—DNN1, NWF, and DNN2—yields better performance compared to sequential training. The NWF’s adaptability during training ensures that the analysis and synthesis transforms are optimized for low-latency processing, which is difficult to achieve with traditional methods. Various training configurations were explored, including different initialization methods, combinations of pretrained weights, and diverse loss functions, to find the most effective setup.
Lightweight Low-Latency Recurrent Neural Networks
The proposed system incorporates Lightweight Low-latency Recurrent Neural Networks (LLRNNs) for both DNN1 and DNN2, achieving impressive computational efficiency. The LLRNNs are responsible for reducing the computational burden while ensuring that the model size remains small and the processing time minimal.
Figure 2 illustrates the flowchart of the LLRNN used in this framework, highlighting its efficient use of recurrent layers to process overlapping frames of the noisy input.
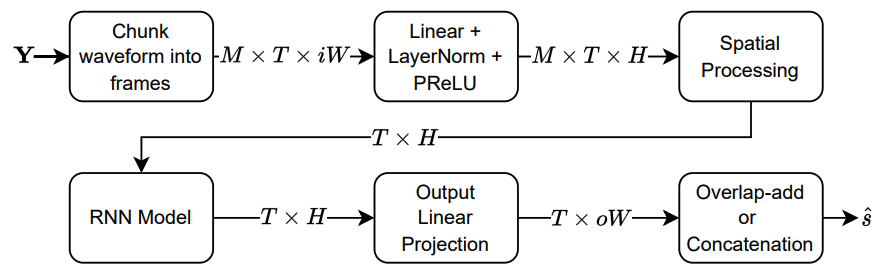
Figure 2: Flowchart of the Lightweight Low-latency RNN used in the framework.
Experimental Results
To evaluate the performance of the proposed model, the authors used the Interspeech 2020 DNS Challenge dataset. Various metrics were employed, including PESQ (Perceptual Evaluation of Speech Quality), SI-SDR (Scale-Invariant Source-to-Distortion Ratio), and STOI (Short-Time Objective Intelligibility). The proposed method outperformed baseline models in terms of both quality and efficiency.
Performance Comparison
Table 1 below compares the proposed Neural Wiener Filter framework with other baseline models like MC-Conv-TasNet and UXNet. The results show significant improvements in perceptual quality and intelligibility scores, especially under resource-constrained conditions.
| Setup | STOI (%) | PESQ | SI-SDR (dB) | Latency (ms) | Parameters (M) | GFLOPs |
|---|---|---|---|---|---|---|
| Noisy | 65.8 | 1.63 | -7.48 | N/A | N/A | N/A |
| LLRNN H=128 | 80.8 | 2.27 | 2.9 | 2 | 0.44 | 1.34 |
| LLRNN H=200 | 83.9 | 2.43 | 4.2 | 2 | 1.03 | 2.78 |
| LLRNN H=256 | 85.6 | 2.51 | 4.9 | 2 | 1.66 | 4.25 |
| LLRNN H=300 | 86.2 | 2.56 | 5.3 | 2 | 2.26 | 5.61 |
| LLRNN H=400 | 87.5 | 2.64 | 6.0 | 2 | 3.97 | 9.40 |
| LLRNN H=512 | 88.3 | 2.69 | 6.5 | 2 | 6.46 | 14.79 |
| MC-Conv-TasNet [20] | 86.3 | 2.57 | 5.6 | 2 | 5.13 | 10.32 |
| MC-CRN-2ms | 84.0 | 2.38 | 3.9 | 2 | 2.32 | 6.73 |
| UXNet-128 [22] | 77.3 | 2.10 | 1.1 | 2 | 0.21 | 0.67 |
| UXNet-256 | 80.9 | 2.25 | 2.9 | 2 | 0.81 | 2.12 |
| FSB-LSTM [15] | 88.2 | 2.68 | 5.8 | 4 | 1.97 | 7.80 |
| Proposed (NWF + DNNs) | 89.1 | 2.70 | 7.0 | 2 | 2.12 | 7.14 |
Table 1: Performance comparison of the proposed framework with other models.
Key Insights from Results
- Higher Quality with Less Compute: The proposed framework provides better PESQ and STOI scores than competing models while using significantly fewer parameters and computational resources. For instance, compared to MC-Conv-TasNet, the proposed model has 56.63% fewer parameters while achieving better performance.
- Effectiveness of Joint Training: Jointly training all components (DNN1, NWF, and DNN2) led to superior results. In particular, using the final output for loss computation rather than intermediate outputs helped improve the efficiency of the training process.
Conclusion
The introduction of the Neural Wiener Filter (NWF) for multichannel speech enhancement represents a major advancement in making speech enhancement both effective and resource-efficient. By working in the time domain and jointly optimizing components, the proposed framework achieves low-latency, high-quality speech enhancement suitable for real-time applications.
This framework provides an efficient solution that can be applied to devices with limited computational capabilities, offering significant improvements over traditional methods in terms of both speech quality and computational cost. If you are interested in exploring this approach further, you can find additional information and resources from the authors at IEEE Xplore.