
Improving Perceptual Quality by Phone-Fortified Perceptual Loss using Wasserstein Distance for Speech Enhancement
Published in Proc. Interspeech, 2021
Improving Speech Enhancement with Phone-Fortified Perceptual Loss
Speech signals are often contaminated by environmental noise, impacting both their quality and intelligibility. This paper, “Improving Perceptual Quality by Phone-Fortified Perceptual Loss using Wasserstein Distance for Speech Enhancement,” introduces a novel approach called Phone-Fortified Perceptual Loss (PFPL) to address these challenges in speech enhancement (SE). Let’s explore what PFPL is, how it improves SE, and what makes it different from previous methods.
The Challenge of Speech Enhancement
Traditional speech enhancement methods often rely on statistical assumptions about the properties of noise and speech. While such methods have had success, they fall short when real-world noises do not match those assumptions. Recent advances in deep learning have greatly improved SE through models like deep neural networks (DNNs), convolutional neural networks (CNNs), and generative adversarial networks (GANs). However, a key question remains: how can we design loss functions that truly capture the perceptual quality of enhanced speech?
To enhance speech effectively, it is crucial that the loss functions used in training are correlated with human perception—not just minimizing the numerical difference between noisy and clean signals but improving how speech actually sounds to the human ear.
Introducing Phone-Fortified Perceptual Loss (PFPL)
The proposed PFPL aims to incorporate phonetic information directly into the training process of speech enhancement models. PFPL achieves this by utilizing latent representations from the wav2vec model—a powerful self-supervised learning model for speech that captures rich phonetic information.
PFPL also leverages Wasserstein distance as its loss measure, which helps in optimally transporting the distribution of noisy speech signals to match the distribution of clean signals. This perceptual loss offers a more meaningful measure compared to traditional point-wise loss functions like mean squared error (MSE).

Figure 1: The architecture of the speech enhancement model using PFPL.
How It Works
The PFPL loss is incorporated into a modified version of the Deep Complex U-Net (DCUnet). In this setup, the input speech is transformed into the frequency domain using short-time Fourier transform (STFT). The enhancement model then predicts a complex ratio mask (cRM) to filter noise from the spectrum. Finally, the enhanced spectrum is converted back to the time domain.
The PFPL computes a perceptual loss based on the phonetic features extracted by wav2vec. These features are rich in phonetic details that correspond to meaningful components of speech like phones and syllables. By measuring the Wasserstein distance between the clean and enhanced speech distributions in this latent space, PFPL better reflects the differences that matter for human auditory perception.
Experimental Results
To assess the effectiveness of PFPL, the researchers used the Voice Bank-DEMAND dataset, which is a well-known benchmark for speech enhancement. Evaluation metrics included PESQ (Perceptual Evaluation of Speech Quality), STOI (Short-Time Objective Intelligibility), and several others.
Visualization and Insights
- t-SNE Analysis: The t-SNE analysis of the wav2vec feature map showed that PFPL can effectively separate phonetic classes, indicating rich phonetic representation (Figure 2).
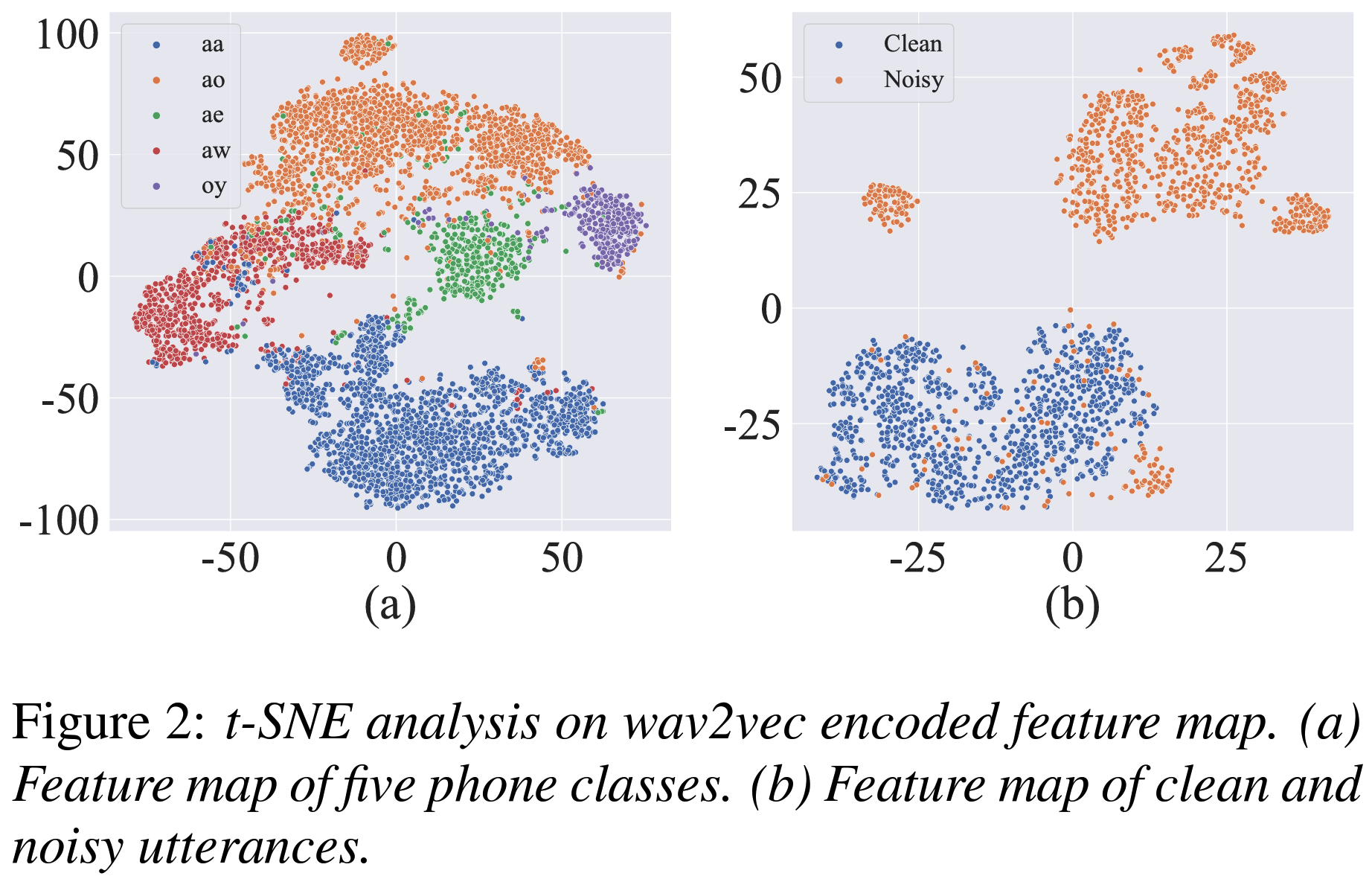
Figure 2: t-SNE plot showing separation of clean and noisy utterances.
- Correlation with Perceptual Metrics: Correlations between PFPL and perceptual quality metrics were significantly higher compared to other loss functions such as MSE or MAE. Figure 3 below shows how PFPL correlates more closely with PESQ and STOI, indicating its effectiveness in training models that produce high-quality, intelligible speech.
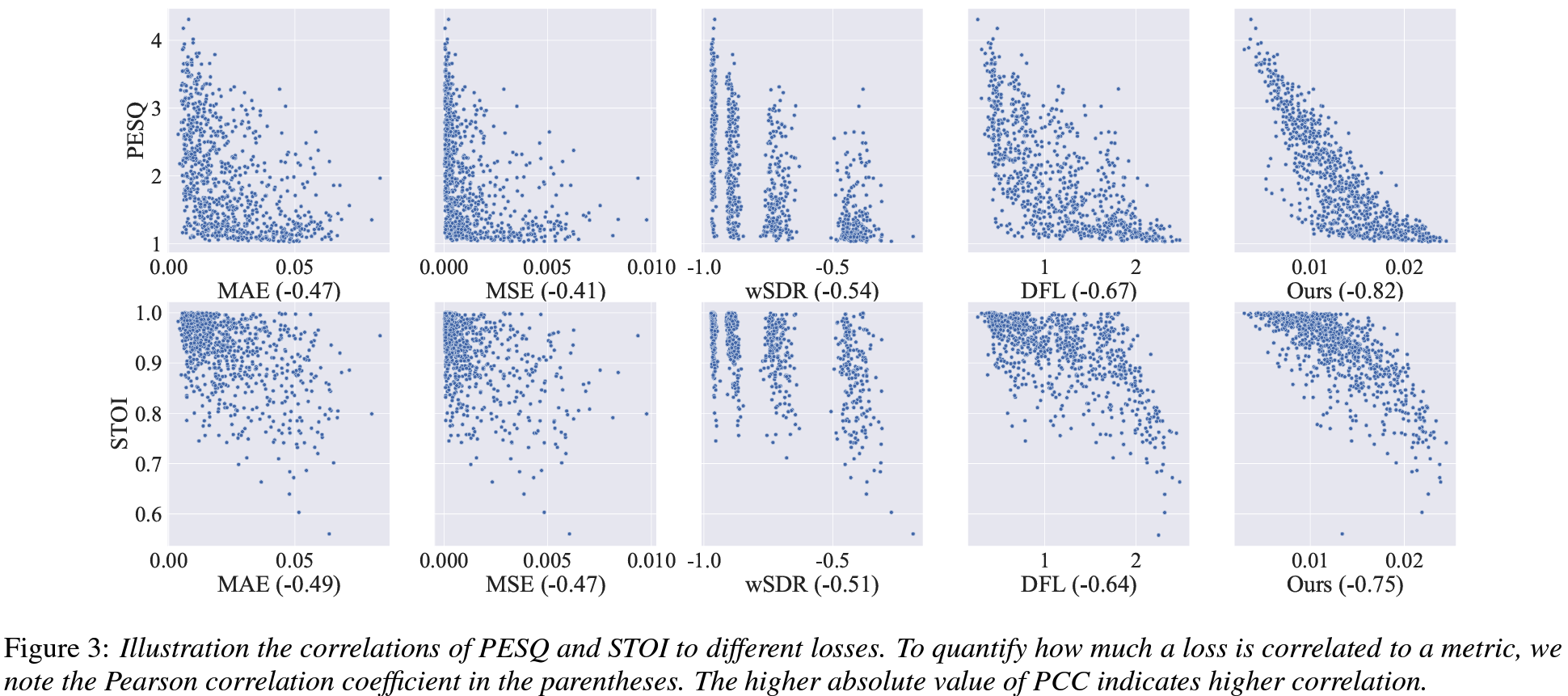
Figure 3: Correlation between different loss functions and perceptual metrics.
- Performance Benchmarks: Table 1 shows that PFPL achieves better perceptual quality (PESQ) and intelligibility (STOI) compared to competing methods like MetricGAN and HiFi-GAN.
| Model | PESQ | CSIG | CBAK | COVL | STOI |
|---|---|---|---|---|---|
| Noisy | 1.97 | 3.35 | 2.44 | 2.63 | 0.92 |
| MetricGAN | 2.86 | 3.99 | 3.18 | 3.42 | 0.94 |
| PFPL (proposed) | 3.15 | 4.18 | 3.60 | 3.67 | 0.95 |
Table 1: Comparison of PFPL with other models on different evaluation metrics.
Conclusion
The Phone-Fortified Perceptual Loss (PFPL) provides a significant improvement in speech enhancement quality by focusing on perceptual and phonetic information. By leveraging the wav2vec model’s phonetic features and the Wasserstein distance, PFPL ensures that the enhanced speech not only minimizes numerical errors but also retains phonetic clarity that is crucial for real-world speech intelligibility. This novel loss function represents a shift towards more human-centric metrics in SE.
If you’re interested in trying this approach, you can find the implementation on GitHub.