Abstract
Generative target speaker extraction (TSE) methods often produce more natural outputs than predictive models. Recent work based on diffusion or flow matching (FM) typically relies on a small, fixed number of reverse steps with a fixed step size. We introduce Adaptive Discriminative Flow Matching TSE (AD-FlowTSE), which extracts the target speech using an adaptive step size. We formulate TSE within the FM paradigm but, unlike prior FM-based speech enhancement and TSE approaches that transport between the mixture (or a normal prior) and the clean-speech distribution, we define the flow between the background and the source, governed by the mixing ratio (MR) of the source and background that creates the mixture. This design enables MR-aware initialization, that the model starts at an adaptive point along the background–source trajectory rather than applying the same reverse schedule across all noise levels. Experiments show that AD-FlowTSE achieves strong TSE with as few as a single step, and that incorporating auxiliary MR estimation further improves target speech accuracy. Together, these results highlight that aligning the transport path with the mixture composition and adapting the step size to noise conditions yields efficient and accurate TSE.
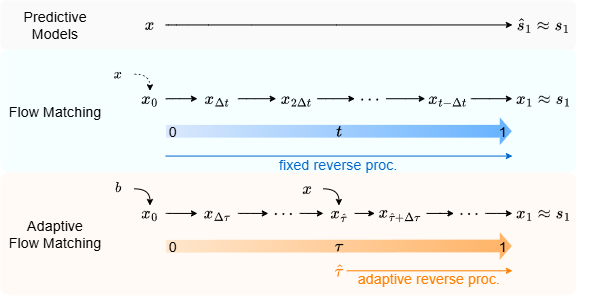
Figure 1: Overview of the AD-FlowTSE framework
Note on Audio Samples
While some of our generated samples may not sound as “crisp” or high-fidelity as outputs from other generative speech models, this difference can be attributed to the following factors:
- Sampling rate: All experiments are conducted on 16 kHz data, which limits the perceptual bandwidth. This can be heard in the original source mixtures.
-
Focus of our method: Our approach emphasizes accurate target speaker extraction, aiming to:
- preserve speaker identity (high SIM), and
- achieve strong speech reconstruction quality (high SI-SDR).
Label explanations:
- Estimated $\hat{\tau}$: Estimated mixing ratio (MR) from the model.
- Oracle $\tau$: Ground-truth mixing ratio (MR) used for generating the mixture.
- $\tau=0$: The TSE model's behavior becomes unpredictable, such as switching to the background speaker.
- $\tau=1$: The TSE model outputs the mixture itself, because the step size is fixed to zero.
Listening Samples
Libri2Mix Clean
| Mixture | Source | Estimated $\hat{\tau}$ | Oracle $\tau$ | $\tau = 0$ | $\tau = 1$ |
|---|---|---|---|---|---|
Libri2Mix Noisy
| Mixture | Source | Estimated $\hat{\tau}$ | Oracle $\tau$ | $\tau = 0$ | $\tau = 1$ |
|---|---|---|---|---|---|
Citation
@inproceedings{hsieh2026adflowtse,
title = {Adaptive Deterministic Flow Matching for Target Speaker Extraction},
author = {Tsun-An Hsieh and Minje Kim},
booktitle = {Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
year = {2026},
}